The most common automated threat we defend our customers against and have observed across the internet is web scraping. It’s even more common than account takeover and carding attacks which are plentiful.
Web scraping is so advantageous and profitable that questionable businesses dedicated to it have begun popping up, essentially selling Scraping as-a-Service. These businesses offer bypasses to bot defenses that allow motivated individuals or organizations to scrape data from other companies.
Why is web scraping so common and why does it occur?
The short answer is money. Here are four interesting ways scraping can be monetized:
- Scraping a brand’s website to create counterfeit websites and harvest personal information
- Scraping content for a competitive advantage or to undermine another business
- Scraping prices for arbitrage
- Scraping pricing errors to get free or deeply discounted items
In Kasada’s State of Bot Mitigation report, nearly 40% of companies surveyed said their organization lost more than 10% of revenue due to web scraping in the past 12 months.
Scraping is unlike any other automated threat – such as credential stuffing, carding, DDoS, etc. – as you must determine whether a scraping request is a bot or human on first contact. Detecting a scraper is a one-time session decision. Any additional attempts to analyze behaviors using machine learning (ML) or other means to stop scraping result in the bot completing its assigned task.
Why is this?
To stop web scraping is like correctly guessing Wordle on the first try
Imagine playing a game of Wordle, but you only have one guess to get it right. With no feedback from prior rounds and additional guesses, you’re swinging in the dark. Could you win? Technically, yes. But it would be a long shot. You don’t have the upper hand against the machine.
The action to stop scraping is similar to playing this modified game of Wordle. It takes only a single GET request to retrieve content or pricing by scraping. So, you as the defender only get one chance to decide correctly. If you can’t, the attacker wins.
Scraping is unlike the other automated threats (credential stuffing, carding, DDoS, etc.), as you must determine whether a scraping request is a bot or human without any opportunities to observe and analyze the interactions within a session. Attempts to analyze behaviors using machine learning (ML) or other means take too long.
While web scraping isn’t illegal, it does pose a risk to security, revenue, and can lead to cases of fraud.
Price Scraping – from scanners to freebies
Scanners
Some instances of price scraping are beneficial, while others are not. For example, in the hospitality industry, hotels have agreements with travel partners allowing them to scan and share their prices through a broader ecosystem. In other cases, scanning prices using scraping bots is bad like those secretly used by competitors to closely monitor and undercut pricing. Sometimes you could also be uncertain of a scraper’s intentions, such as those looking to exploit arbitrage opportunities by exploiting price differences across marketplaces.
Regardless of the intention, price scraping is very difficult to stop. First, operators disguise their bots to look either like good bots (such as Google bots that crawl your site) or humans. When attempting to disguise themselves as humans, scraping bots are disguised using residential proxy networks so every request issued appears like a new session. Even trickier, residential proxy networks can be customized further for a specific website, using geo-targeting and device types to blend in with legitimate shoppers.

Figure 1: A global retailer experienced a two-day scraping attack in an attempt to collect stock price information and product availability. The attack was highly distributed, hidden behind a residential proxy network consisting of nearly 19,000 IP addresses, 1,400 user agents, and 28 device types.
Freebies
The recent emergence of “freebie bots” creates another price scraping problem that many retailers must now contend with. Freebie bots work similar to price scanners used to scrape prices, but prey on pricing errors made by the retailer. When the bot detects a price error (configurable $0 or any percentage discount off of MSRP), it triggers automation to purchase the product before the pricing error gets corrected. There are people all over the Internet promoting freebie bots as a means to get thousands of dollars of free goods and services.
Freebie bots present all of the detection challenges associated with price scanners in that they also rely on residential proxies to fly beneath the radar of detection systems. But the challenge is amplified by the fact that (a) these bots are sold to consumers cheaply for them to use on their own and (b) they repeatedly scan within very small time increments to discover pricing errors before they are discovered and corrected.
This presents a scenario where retailers have to contend with freebie bots at a massive scale. Tens of thousands of users are all issuing requests across the entire product catalog – every couple of seconds or less – solely to find the occasional pricing error to get their free goods.

Figure 2: “Freebie bots” such as Freebie Frenzy have emerged as the latest price scraping challenge for retailers. In addition to the financial impact of having to sell items at no cost, they impose tremendous scale challenges due to the volume and frequency of requests imposed by B2C, while harming the performance and availability of websites.
Web Scraping – from IP theft to counterfeit websites
Scraping product catalogs and stealing intellectual property
Content scraping is different from price scraping but works in a similar way. A request is made to load and retrieve the page, and then HTML loads the page once since they can’t stop the first page load. At this point, the scraper has what they need before the business has a chance to classify and stop it. There’s an incredibly short window to decide whether a bot or human is sending the request.
Competitors scrape images or whole-page content to piggyback on the investment (i.e. time, effort, money) you’ve already made into developing content, to reuse on their site. Content scraping can also be malicious in an attempt to sabotage a competitor’s search ranking by intentionally duplicating their content.
While those tech-savvy enough to write scripts to scrape websites can do so, scraping as a service has emerged such that anybody with a credit card can scrape a website. These services are available for hundreds of popular websites and can be customized for specific websites of your liking. Often these services are part of a broader portfolio, including stealthy proxies that ensure scraping requests go undetected.

Figure 3: Companies like BrightData (formerly Luminati) offer a range of no-code options for website scraping. These services are layered with their proxy network infrastructure (including fully managed options that include site-specific browser cookies, HTTP header requests, emulated devices, and CAPTCHA solvers) to remain undetected by anti-bot systems.
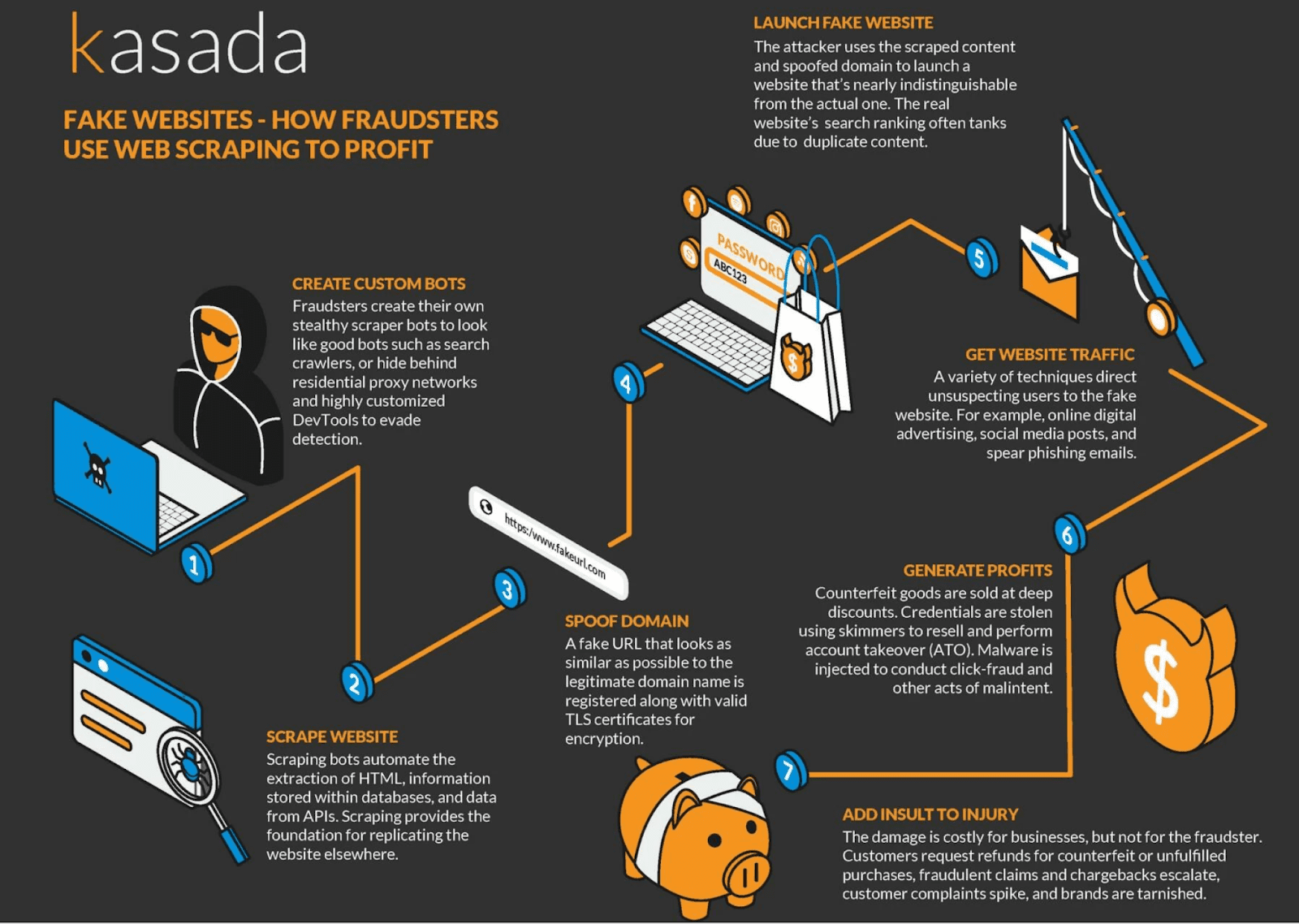
Scraping provides the basis for counterfeit websites
Website scraping can be used as the basis of counterfeit profit schemes. The attacker uses the scraped content and spoofed domain to launch a website that’s nearly indistinguishable from the actual one with various techniques to direct unsuspecting users to the fake website. For example, online digital advertising, social media posts, and spear phishing emails could all point to the counterfeit site. These sites can have a variety of goals:
- Sell counterfeit goods at deep discounts.
- Steal credentials to perform account takeover (ATO).
- Inject malware into links to conduct click-fraud and other acts of malintent.
The damage is costly for businesses, but not for the fraudster. Customer refund requests soar for counterfeit or unfulfilled purchases, fraudulent claims and chargebacks escalate, customer complaints spike, and the brand’s reputation takes a hit. Counterfeiting has grown from a $30B problem in the 1980’s to now a $600B problem.
Services that comb the web to find counterfeit websites and other forms of scraping could be helpful, in addition to stopping scraping on its own. But fundamentally they aren’t solving the root cause which means there’s a delay in identifying the rogue sites and you have to pay the heavy tax of having your website continuously scraped (cost, performance, SEO).
Rising to the scraping challenge
Scrapers continue to evolve. Both in their level of sophistication and in the new ways they exploit different business models. Many anti-bot solutions have given up on detecting scrapers since it requires fast client-side processing rather than slower server-side processing that takes time to analyze behaviors and apply machine learning.
In addition, anti-bot solutions that leverage CAPTCHAs or behavioral data (mouse movements or clicks) to detect automation rely on JavaScript to load with the page before the solution can work. This prohibits them from stopping the actual page load and renders them useless against scraping.
The most effective way to stop price and web scrapers is to look for traces of automation instead of behaviors and to assume that all requests are guilty until proven innocent.
Kasada is by and large able to stop web scrapers client-side on the first request by being experts at identifying such traces. However, we understand and anticipate that highly motivated attackers will retool and change their methods to get by client-side defenses. To reduce the occurrence of such events, we employ various precautions:
- Randomize client-side defenses so that what might work for an adversary on one attempt, is unlikely to work for future attempts.
- Combine layers of defense such as security engineering, analytics, and threat intelligence to allow us to pivot quickly if and when an adversary averts client-side defenses.
- Our closed-loop architecture allows us to take what is learned server-side to deploy new client-side defenses across our entire customer base in less than 30-seconds.
To stop web scraping, businesses need a modern, agile platform. This is why many of the largest hotels, eCommerce, and real estate brands have chosen Kasada. We’re able to stop persistent scraping attempts in addition to other automated threats like credential stuffing, carding, and inventory denial.
Getting it right the first time around
Going back to the Wordle analogy, now instead of guessing on the first try and failing, Kasada inspected the request before the page load so we’ve already seen the answer in the code – It’s all about being agile and knowing exactly where to look. ;)

Want to learn more?

KasadaIQ’s Q1 Insights: How AI Became Adversary Infrastructure
KasadaIQ’s Q1 2026 Threat Intelligence Report highlights a structural shift in automated threats: AI is now embedded across the adversary lifecycle. From large-scale account commoditization to verification bypass and AI agent exploitation, organizations face a rapidly evolving and industrialized threat environment.

KasadaIQ’s Q1 Insights: How AI Became Adversary Infrastructure
KasadaIQ’s Q1 2026 Threat Intelligence Report highlights a structural shift in automated threats: AI is now embedded across the adversary lifecycle. From large-scale account commoditization to verification bypass and AI agent exploitation, organizations face a rapidly evolving and industrialized threat environment.
