No one is using ChatGPT to scrape your data… yet. Despite the hype – and in their current form – Large Language Model’s (LLM’s) tendency to hallucinate is a deal breaker for individuals who want your data. The reality is, the task of taking your data probably isn’t that hard anyway.
Scraping content is a niche, hard-to-assess problem that sits firmly within multiple “grey zones” for online businesses:
- Sometimes scraping is legal, sometimes it’s not.
- You want your competitors’ data, but you don’t want them to have yours.
- It’s not a “cyber” problem, yet the tooling used to defend these “attacks” is often owned and operated by your cyber team.
It’s a challenging problem to grapple with on many levels.
The legality of web scraping has been tested several times recently in the US. Initially, it was tested by social media platforms and more recently in response to the data “acquisition” practices of the growing number of AI companies with models that need to be trained. The legal stoushes have turned into a cat vs. mouse game that rivals the attempts to prevent web scraping at a technical level.
The Office of the Australian Information Commissioner and eleven of its international counterparts have recently released a statement confirming that mass data scraping incidents that harvest personal information can constitute a reportable data breach. Whilst targeted specifically at social media platforms, this statement also refers to “operators of websites that host personal data information.”
Let’s talk about AI
In 2023, other than media hype, there is little to motivate someone to turn to AI to scrape content. In all likelihood, that will not remain the case. There is probably a VC-backed AI startup in the Bay Area building this tool as we speak. Focusing on the potential for someone to use AI to automate the scraping of your content is not the problem that you should be focused on. The real problem, one that represents an existential threat to many online businesses, is that AI companies are using your data to train their models.
Stack overflow saw a 15% reduction in web traffic in the month following the release of ChatGPT. Elon Musk referred to it as “Death by LLM”. In an interview with The New York Times, Reddit’s founder and chief executive Steve Huffman said, “The Reddit corpus of data is really valuable. But we don’t need to give all of that value to some of the largest companies in the world for free.”
So, let’s stop for a minute and reconsider the current state of scraping.
What’s the problem with web scraping?
If data is the new oil, then web scraping is the new oil rig. Whilst both data and oil are ubiquitous resources, data is far more abundantly available. Data comes in all shapes and sizes. Alternative datasets – such as satellite images, social media posts, geolocation data, web data, and news feeds – all provide the promise of a sustainable competitive advantage.
Deloitte estimates that by 2030, the global revenue generated by alternative-data providers across all industries could grow by as much as 29x, at a compound annual growth rate of 53%, and possibly reach US$137 billion.
The traditional view is that web scraping is simply designed to capture publicly available data at scale. As such, scraping is often considered a cost of doing business rather than a cyber risk. This assumes the motive of the scraper is not malicious.
Criminal groups, motivated by profit and not bound by legality, also use scripts to harvest data. Credential abuse attacks serve as a great example. Credential abuse tooling, such as OpenBullet, is a repurposed web scraping tool that targets the login endpoint to harvest valid credentials. These credentials and the contents of the account they protect have value in criminal marketplaces. Their modus operandi is simple – identify valid credentials, log in, and scrape as much PII as possible whilst exploiting any immediate option for monetisation. The PII data accessed by the tools also warrants a data breach, with the growing potential for hefty fines.
Let’s stop to consider the recent DuoLingo incident. A web scraper was used to extract the personal information of 2.6M users from a public-facing API. This represents 3% of their total users. The data harvested included publicly available data as well as private data. There were two stages to the scraping attack:
- Active accounts were identified by a brute force attack on the validated email endpoint
- Once confirmed, these accounts were submitted as a parameter to an API request.
In this incident, scraping can be considered an enumeration vector, enabling a mass data collection event. Is this a data breach or a data leak? What is the difference? According to the OAIC statement, this would be considered a reportable event.
Why is web scraping so hard to stop?
Once you arrive at the decision to stop web scraping, you’ll find that it is a surprisingly challenging problem to solve, particularly if you possess a dataset that is interesting to others. If your data is unique and has a market value, you are in for a long-term battle.
Most web scraping attacks are simply a series of highly targeted HTTP GET requests. And herein lies why they are so notoriously difficult to prevent. Traditional tooling, like a Web Application Firewall (WAF), relies on assessing request headers, request bodies, and network layer data. A WAF is looking for something malicious or a pattern of behaviour in a set of requests (rate limit). WAFs are unable to detect scraping as the requests are benign and it is trivial to rotate the requests through a highly distributed residential proxy network so that there is no discernible pattern
Equally, most anti-bot solutions are designed to protect data submissions, not page loads. Think about a CAPTCHA solution. The CAPTCHA scripts need to load in the page in order to trigger the processes required to protect a subsequent data submission. Likewise, many bot detection solutions are built around the concept of detecting anomalous patterns in mouse movements, clicks, etc. These solutions simply do not work well on GET requests, so they are ill-equipped to solve scraping solutions.
Adding to the challenge, most web scrapers are written by highly competent software engineers – they understand how applications work and can easily evade the gaps in these solutions to extract their desired dataset.
Let’s conduct a risk assessment on web scraping!?
Actually, let’s not. The tendency to assess web scraping as a cyber threat is misguided. There is only one scenario where web scraping is a cyber risk and this was clearly exhibited in the Optus breach in 2022. Web scraping is a means to extract data at scale. In the Optus incident, someone identified an unprotected API endpoint that served PII data and used a web scraper to extract all the data accessible from that endpoint.
Assessing the likelihood of web scraping
There are many more scenarios where web scraping results in a negative outcome whilst not being considered a cyber risk. The challenge is that web scraping is most likely to be happening if you have public-facing web assets. Google does no evil, right? Most companies have little visibility into who is scraping them or why they are being scraped, which compromises the assessment of the business impact.
Assessing the impact of web scraping
Let’s assess the potential impact of an eCommerce company having their pricing catalog scraped. A competitor scraping your pricing catalog is an incredibly common scenario. The purpose of scraping a competitor’s catalog is not just to understand the price of their goods. The greater value is in reverse engineering their pricing strategy.
In a competitive market where price is often a differentiator, the key piece of data is not only what the price is but when it changes. If you know when your competitor changes the price of a given product you can nullify or reclaim a price advantage – if you automate this process, you will always be a step ahead. So each web scraper is most likely scraping each product at least once an hour, if not more frequently.
Morningstar expects “Amazon Australia to grow faster than its local competitors and to maintain intense price-based competition in the medium term, hindering JB Hi-Fi’s and Harvey Norman’s market shares and operating margins.” So, the risk associated with web scraping is centered around price-based competition – with Amazon Australia representing a substantial business risk.
So here we are in another web scraping grey area: Maintaining a competitive advantage in a price-oriented market is a business risk that will never be assessed in a cyber risk assessment. Yet the tooling required to prevent web scraping will almost certainly be owned, operated, and paid for by the security team.
Therefore the most common outcome is that no one owns the problem and the tooling doesn’t work. A true corporate “see no evil, hear no evil” scenario.
Who the hell is scraping my data anyway?
When most people think about “bots” they probably think about malware-infected machines conducting traditional cyber attacks like DDoS. For most organisations, these traditional attacks are infrequent. There is an attack, followed by a period of dormancy. For most, these events occur at low frequency – once a year or less. The criminals who launch these attacks are opportunistic and will simultaneously target a large number of companies.
Non cyber-related bot attacks present very differently. The communities that conduct these attacks are rarely breaking the law. They operate in the open and are motivated by the potential to monetise the output of their bot. A hype bot secures limited-release products for their resale value. A data scraper secures data that is leveraged in other ways. The path to monetisation is varied:
- some actors package data for resale,
- others offer targeted data acquisition,
- others sell analysis products based on the data,
- others make investment decisions based on the insights provided by the data.
The challenge for scrapers is that they need to acquire the full data set to conduct accurate analysis. For example, a scraper that is looking to assess the state of the real estate market needs to know exactly which properties are available today, the price, length on market, etc. Then, they need to update that either weekly or monthly.
The key challenge therefore is to acquire the data whilst remaining undetected. This challenge is made substantially easier given the aforementioned grey areas associated with scraping – no one owns the problem and the tooling most likely fails to detect the activity unless the scraper is accidentally too aggressive.
Is my data “alternative” and should I care?
What is the value of an organisation’s publicly available data? If you publish content on the web, is it free for anyone to take? Hedge funds and the broader investment communities have already mastered the art of using “alternative data” to augment decision-making.
Given that all bots are motivated by money, it should come as no surprise to learn that alternative data originated in the finance sector. According to the official definition, alternative data is information about a particular company that is published by sources outside the company, providing unique and timely insights into investment opportunities.
In a recent example, satellite images were used to assess and compare activity levels at Amazon distribution facilities over a seven-year period.
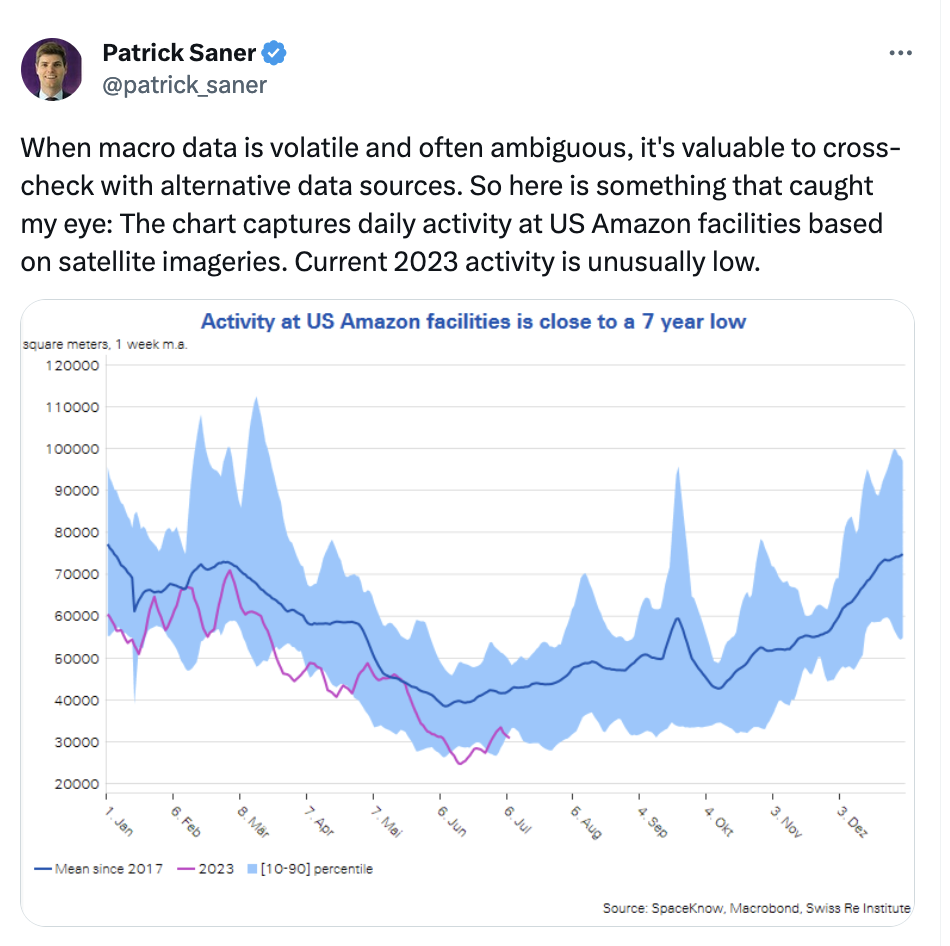
It should come as no surprise why certain industries’ data is more attractively alternative than others. The finance industry’s fascination with the property markets or the job market is an obvious one. News sites are equally targeted. The key to considering your own situation is to understand what data is made available and who may use it for their competitive advantage.
My AI model needs your data
Financial institutions are not the only ones with a thirst for alternative data. There is a rapidly escalating issue associated with the awakening of the AI industry.
All AI models need to be fuelled with data. The more specific, current, and unbiased the data the better. The first step in selecting data sources for an AI model involves identifying all the available data for the specific problem. The sources of these data vary – the public web, online data sets, any number of public APIs, etc. Many of these datasets were created and published before the concept of LLM training existed.
Stackoverflow is a great example, the website experienced a dramatic reduction in traffic volumes, impacting their advertising revenue model as programmers first started to use GitHub co-pilot and then ChatGPT to ask programming questions.
So basically we have businesses like Stackoverflow, Reddit, and Twitter, sitting on top of a mountain of data, struggling to monetize it, while AI companies, via web scraping, are using this data to train their models and raise tons of money from VCs.
The Washington Post recently published an analysis of the websites Google used to train the C4 dataset and train models including Google T5 and Facebook’s LLaMa. Within the 15 million websites scraped to build the dataset are most household names and several that give cause for concern. The take-home message here is that your data is being consumed in new ways that you’ve probably not previously considered.
Summary
So, if you shouldn’t care about chatGPT being used to scrape your website, what should you care about? The bigger issue is that most businesses have limited visibility and undefined ownership of the business impact caused by web scraping. The potential impact of web scraping is escalating as the twin forces of alternative data and AI training both rapidly increase in size and complexity. This is a problem that sits in the middle of the Venn diagram of business, IT, and Security. The first step is to dedicate ownership of the problem to an individual within your organization, and then that person must take steps to improve organizational visibility of web scraping and what it means for your business.
Want to learn more?

KasadaIQ’s Q1 Insights: How AI Became Adversary Infrastructure
KasadaIQ’s Q1 2026 Threat Intelligence Report highlights a structural shift in automated threats: AI is now embedded across the adversary lifecycle. From large-scale account commoditization to verification bypass and AI agent exploitation, organizations face a rapidly evolving and industrialized threat environment.

KasadaIQ’s Q1 Insights: How AI Became Adversary Infrastructure
KasadaIQ’s Q1 2026 Threat Intelligence Report highlights a structural shift in automated threats: AI is now embedded across the adversary lifecycle. From large-scale account commoditization to verification bypass and AI agent exploitation, organizations face a rapidly evolving and industrialized threat environment.
